It's been a while (in fact: it's been to long) since I've last posted a blog entry. The reason for this was that I've been working as a team-lead the last couple of months. Therefore I was more 'occupied' with leading a team, then I was with inventing/discovering great BI 7.0 solutions....
But as I'm back in the saddle, I'm proudly presenting my first 2010 blog entry:
Within the DTP-extraction tab, you're able to set a filter to control the data you're going to extract:
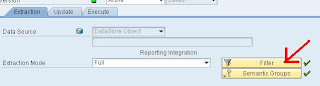
The standard coding which will be displayed will be something like this:
read table l_t_range with key fieldname = ' '.
l_idx = sy-tabix.
if l_idx <> 0.
modify l_t_range index l_idx.
else.
append l_t_range.
endif.
Please be aware that, if l_idx = 0 and thus no entry is found in table l_t_range, you also have to fill in the
fieldnameEg. Usually, for filling a range, the following code is entered:
l_t_range-sign = 'I'.
l_t_range-option = 'EQ'.
l_t_range-low = 'something'
This coding is sufficient when the read statement
(read table l_t_range with key fieldname = 'whatever') finds an entry in table l_t_range...and thus l_idx <> 0.
When no entry is found (and thus l_idx = 0) you also have to add the following line to the code
l_t_range-fieldname = 'FIELDNAME'.otherwise filling the range has no added value...as the system does not know for which field the range should be filled....